1. Getting started¶
rastercube is a python package to store large geographical raster collections on the Hadoop File System (HDFS). The initial use case was to store and quickly access MODIS NDVI timeseries for any pixel on the whole planet. In addition, rastercube provides facility to process the data using Spark.
It allows you to turn a set of raster images (e.g. MODIF HDF files) into a 3D cube that enable efficient querying of pixels time series.
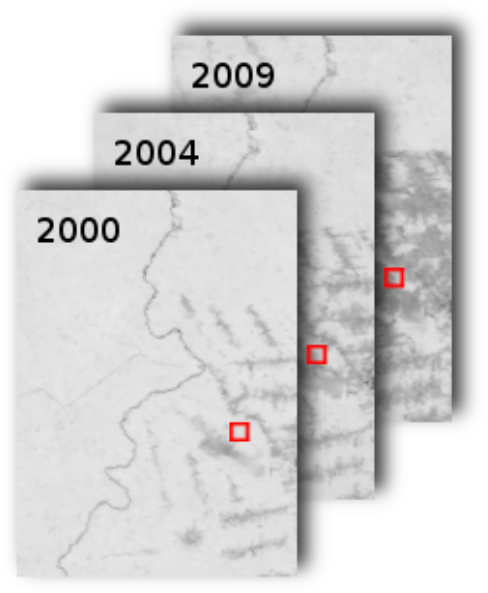
It was initially written to perform pantropical land-cover change detection in the terra-i project, based on MODIS NDVI imagery.
The central component is the rastercube.jgrid.jgrid3.Header class
All the geographical computations are handled by gdal.
1.1. Environment variables¶
Example:
export RASTERCUBE_TEST_DATA=$HOME/rastercube_testdata
export RASTERCUBE_DATA=$TERRAI_DATA
export RASTERCUBE_WORLDGRID=$TERRAI_WORLDGRID
export RASTERCUBE_CONFIG=$TERRAI_DATA/1_manual/rastercube_config.py
1.2. Configuration¶
Rastercube’s configuration options are defined in the rastercube.config
module. To override options, create a rastercube_config.py file on your
file system and have the $RASTERCUBE_CONFIG environment variable point
to it. For example:
export RASTERCUBE_CONFIG=$RASTERCUBE_DATA/1_manual/rastercube_config.py
With rastercube_config.py containing:
MODIS_HTTP_USER="foo"
MODIS_HTTP_PASS="bar"
1.3. Worldgrid¶
A worldgrid is a (chunked) georeferenced nD (n >= 2) array covering the whole earth. The first two dimensions are spatial dimensions and the third dimension is usually time.
The original use case for which the format was designed was to store MODIS NDVI timeseries for the pantropical areas (south america, africa and asia). MODIS NDVI images have a frequency of 8 days (if you use Terra and Aqua) and a ground resolution of 250x250m.
In the case of MODIS NDVI, there is also a quality indicator. So you would have two worldgrids : one containing NDVI and one containing quality. You could imagine more worldgrids if you were interested in other MODIS bands. You can also have worldgrid for other data types such as Global Land Cover data.
The rastercube package provides a simple API to store worldgrids on the Hadoop File System
1.4. Date management¶
Geographical rasters are usually downloaded as timestamped tiles. When creating a worldgrid, you want to ensure that you have the same dates available for each tile so you have a homogeneous time axis for the whole grid.
This is done by collecting the available date for a particular model tile and
storing them in a .csv. See the ndvi_collect_dates.py script.
Note
If a particular MODIS tile is missing a date (this can happen due to satellite malfunction), you can just manually create a tile with all bad QA/NDVI
1.5. Input data files structure¶
The input data (e.g. the MODIS HDF tiles, the GLCF tiles) that are imported into worldgrid need to be stored on a traditional unix filesystem (or on NFS).
The environment variable $RASTERCUBE_DATA should point to the location
where the data is stored.
For example, here is the layout used in the terra-i project. rastercube
assumes that you have similar 0_input and 1_manual directories.
0_inputshould contain all input raster data1_manualshould contain some manually created files like the NDVI dates .csv
/home/julien/terra_i/sv2454_data
├── 0_input
│ ├── glcf_5.1
│ ├── hansen_dets
│ ├── landsat8
│ ├── MODIS_HDF
│ ├── modis_www_mirror
│ ├── prm
│ ├── terrai_dets
│ └── TRMM_daily
├── 1_manual
│ ├── hansen_wms
│ ├── ndvi_dates.csv
│ ├── ndvi_dates.short.csv
│ ├── ndvi_dates.terra_aqua.csv
│ ├── ndvi_dates.terra_aqua.short.csv
│ ├── ndvi_dates.terra.csv
│ └── qgis
├── 2_intermediate
│ ├── logs
│ ├── models
│ ├── models_rawndvi
│ └── terrai_dets
├── experimental
│ ├── glcf_dets
│ ├── glcf_dets_2
│ ├── land_cover
│ ├── qgis
│ ├── test2.hdf
│ └── test.hdf
1.6. Building the Cython modules¶
rastercube relies on Cython modules for some operation. Those cython modules need to be compiled. To do so, you
can simply run the build.sh script in the root directory. There are a few gotchas though :
1.6.1. Building with Anaconda on OSX¶
If you are using OSX and use Anaconda’s python, you need to make sure that cython will build with Anaconda’s GCC and NOT clang or the system GCC. This is because Anaconda’s python is linked with libstdc++ (the GCC standard library) and OSX ships with a pre-C++11 version of libstdc++, which might lead to problems.
In short, ensure that if you run which gcc, it either points to Anaconda’s gcc or to a recent homebrew installed
GCC.
You can control the C/C++ compiler used by setting the CC and CXX environment variables when building
CXX=/usr/local/bin/gcc-7 CC=$CXX ./build.sh
1.6.2. Building to use through Spark on a cluster¶
When you use rastercube with a Spark cluster, Spark will distribute the python egg (the output of build.sh) to all Spark worker nodes. Since we use native modules, you need to ensure that the egg is built for the correct CPU architecture. Assuming you have a homogeneous cluster, the easiest way to do so is to build rastercube and start the spark job from one of the cluster node.
Otherwise, if you build from a Linux machine, you need to make sure that GCC targets an architecture that is common
to both your Linux machine and the cluster. You can play with the -march option in setup.py to target
the correct CPU type, going all the way to march=i386 which should work but could lead to lower performance.